Database interoperability in Python utilising the Repository Enterprise Pattern

Part 3 of 3 in Software Odds and Ends
Introduction

Recently, I’ve been knee-deep in Python. Leave me in a dark room with a tea, an IDE, and a programming problem and I’m happy, so it’s been quite enjoyable.
The problem in question was a monitoring and visibility platform I’d built from scratch — observing around 8,000 CI/CD builds a month and presenting dashboards at the executive level, running for under £1 a month in operational costs. Off-the-shelf alternatives for the same job start at around £12k a month. The platform was originally backed by DynamoDB, which was cheap and sufficient when the dataset was small. Over time the dataset grew and the queries got complex enough that I wanted to migrate to Postgres — partly for the performance benefits that come with a proper relational model, and partly because QuickSight, which I’d been using for visualisation, had started to feel clanky. Moving to Postgres opened up the wider ecosystem: Grafana, in particular, was where I wanted to land.
That migration required restructuring how the application talked to its database — and that’s where the Repository pattern came in. I sat down and thought there must be a cleaner way to build in multiple database backends and still have code that makes sense in six months. Turns out there was. The pattern is well-documented by Martin Fowler in Patterns of Enterprise Application Architecture — I initially leaned on Microsoft’s interpretation while my copy was in the post, and when it arrived it reaffirmed I’d had the right idea.
For the demo, I needed a domain model — and with a small Discworld figurine on my desk and a stack of Pratchett novels on the go, that decision made itself.
The goal
By the end of this article, readers will understand:
- What the Repository pattern is and what problem it solves.
- How to implement abstract repository interfaces in Python using
abc.ABCand@abstractmethod. - How to build concrete implementations for different persistence backends — JSON file storage and SQLite (Structured Query Language).
- How a factory method wires the right backend at runtime without the rest of the application caring which one it is.
- Why decoupling domain models from persistence makes large migrations significantly less painful.
Prerequisites
- Comfortable with Python and object-oriented programming (OOP) — abstract classes and inheritance in particular.
- Basic familiarity with SQL and NoSQL concepts. If either is new ground, the links below are good starting points.
SQL (relational)
NoSQL
Python 3.10 or later is needed to run the demo application at the end.
The Repository pattern
A Repository interface sits between your domain objects and the data layer. The domain doesn’t know or care whether data ends up in a relational database, a document store, or a flat file — it just calls record() and gets a result back. All the persistence logic lives in concrete implementations behind that interface, and the business logic stays where it belongs.
This pattern is documented by Martin Fowler in Patterns of Enterprise Application Architecture. Microsoft also has a solid write-up of their interpretation here. Both are worth reading — Fowler for the theory, Microsoft for a practical take that maps well to Python.
When something changes in the persistence layer — a migration, a new backend, a test environment that can’t reach production — none of that touches the domain.
The Discworld domain model
For the purposes of the demo, I’m modelling which Discworld characters appear in which books.
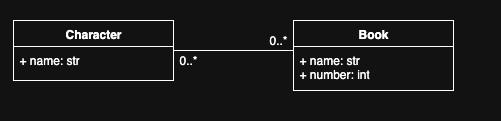
Three dataclasses cover the domain:
from dataclasses import dataclass
@dataclass
class Book:
name: str
number: int
@dataclass
class Character:
name: str
@dataclass
class CharacterToBookMapping:
book: Book
character: CharacterNo persistence logic here. No database imports, no file handles — just the shape of the problem domain.
Abstract repository interfaces
Each domain class gets a corresponding abstract repository defining the interface any concrete implementation must satisfy. A shared RepositoryResult enum gives every implementation a common return type — callers check SUCCESS or FAILED rather than catching backend-specific exceptions.
from __future__ import annotations
from abc import ABC, abstractmethod
from enum import Enum, unique
from discworld_cli.domain.models import Book, Character
@unique
class RepositoryResult(str, Enum):
SUCCESS = "success"
FAILED = "failed"
class BookRepository(ABC):
@abstractmethod
def record(self, book: Book) -> RepositoryResult: ...
class CharacterRepository(ABC):
@abstractmethod
def record(self, character: Character) -> RepositoryResult: ...
class CharacterToBookMappingRepository(ABC):
@abstractmethod
def record(self, book: Book, character: Character) -> RepositoryResult: ...Python offers two ways to define interfaces: abc.ABC with @abstractmethod, and structural typing via Protocol. Coming from C#, I find Protocols more intuitive — duck typing suits Python’s character, and the structural approach removes the need for explicit inheritance.
For this use case I went with ABC. These repositories are tightly coupled to the domain by design — BookRepository is always going to be about Book objects. For an SDK with a plugin architecture where third parties supply their own implementations, Protocols would be the better fit.
Concrete implementations
JSON file storage
JSON requires no infrastructure — no running database, no connection string. It’s the backend I reach for in local development and tests where standing up a real database would be friction without benefit.
The implementation uses atomic writes: data goes to a temp file first, then replaces the target. A partial write that gets interrupted leaves the original file intact.
from __future__ import annotations
from pathlib import Path
from typing import Any
import json
import tempfile
import os
from os import PathLike
Pathish = str | PathLike[str]
def _read_list(path: Path) -> list[dict[str, Any]]:
if not path.exists() or path.stat().st_size == 0:
return []
try:
data = json.loads(path.read_text(encoding="utf-8"))
return data if isinstance(data, list) else []
except json.JSONDecodeError:
return []
def _atomic_write_text(path: Path, text: str) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
with tempfile.NamedTemporaryFile(
"w", delete=False, dir=path.parent, encoding="utf-8"
) as tmp:
tmp.write(text)
tmp_path = Path(tmp.name)
os.replace(tmp_path, path)
def _write_list(path: Path, data: list[dict[str, Any]]) -> None:
_atomic_write_text(path, json.dumps(data, indent=2, ensure_ascii=False))The concrete repository classes sit on top of those helpers:
from dataclasses import dataclass
from discworld_cli.domain.repositories import (
BookRepository,
CharacterRepository,
CharacterToBookMappingRepository,
RepositoryResult,
)
from discworld_cli.domain.models import Book, Character
@dataclass
class JSONFileBookRepository(BookRepository):
file_path: Pathish
def record(self, book: Book) -> RepositoryResult:
path = Path(self.file_path)
items = _read_list(path)
exists = any(
i.get("name") == book.name and i.get("number") == book.number
for i in items
)
if not exists:
items.append({"name": book.name, "number": book.number})
_write_list(path, items)
return RepositoryResult.SUCCESS
@dataclass
class JSONFileCharacterRepository(CharacterRepository):
file_path: Pathish
def record(self, character: Character) -> RepositoryResult:
path = Path(self.file_path)
items = _read_list(path)
if not any(i.get("name") == character.name for i in items):
items.append({"name": character.name})
_write_list(path, items)
return RepositoryResult.SUCCESS
@dataclass
class JSONFileCharacterToBookMappingRepository(CharacterToBookMappingRepository):
file_path: Pathish
def record(self, book: Book, character: Character) -> RepositoryResult:
path = Path(self.file_path)
items = _read_list(path)
entry = {
"book": {"name": book.name, "number": book.number},
"character": {"name": character.name},
}
exists = any(
i.get("book", {}).get("name") == entry["book"]["name"]
and i.get("book", {}).get("number") == entry["book"]["number"]
and i.get("character", {}).get("name") == entry["character"]["name"]
for i in items
)
if not exists:
items.append(entry)
_write_list(path, items)
return RepositoryResult.SUCCESSSQLite
The SQLite implementation needs shared connection management and schema initialisation. A base class handles both — concrete repositories inherit from it alongside their abstract interface, so the connection setup happens once rather than being duplicated across three classes.
from __future__ import annotations
import sqlite3
from os import PathLike
Pathish = str | PathLike[str]
SCHEMA_SQL = """
PRAGMA foreign_keys = ON;
CREATE TABLE IF NOT EXISTS books (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
number INTEGER NOT NULL,
UNIQUE(name, number)
);
CREATE TABLE IF NOT EXISTS characters (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL UNIQUE
);
CREATE TABLE IF NOT EXISTS character_book_mappings (
book_id INTEGER NOT NULL,
character_id INTEGER NOT NULL,
PRIMARY KEY (book_id, character_id),
FOREIGN KEY (book_id) REFERENCES books(id) ON DELETE CASCADE,
FOREIGN KEY (character_id) REFERENCES characters(id) ON DELETE CASCADE
);
"""
class _SQLiteRepoBase:
def __init__(self, db: Pathish | sqlite3.Connection):
if isinstance(db, sqlite3.Connection):
self.conn = db
self._owns = False # Don't close a connection we didn't open
else:
self.conn = sqlite3.connect(db)
self._owns = True
self.conn.row_factory = sqlite3.Row
self.conn.executescript(SCHEMA_SQL)
self.conn.commit()
def close(self) -> None:
if self._owns:
self.conn.close()
def __enter__(self):
return self
def __exit__(self, *exc):
self.close()The concrete repositories inherit from _SQLiteRepoBase alongside their abstract interface:
from dataclasses import dataclass
from discworld_cli.domain.repositories import (
BookRepository,
CharacterRepository,
CharacterToBookMappingRepository,
RepositoryResult,
)
from discworld_cli.domain.models import Book, Character
@dataclass
class SQLiteBookRepository(_SQLiteRepoBase, BookRepository):
db: Pathish | sqlite3.Connection
def __post_init__(self):
super().__init__(self.db)
def record(self, book: Book) -> RepositoryResult:
try:
self.conn.execute(
"INSERT OR IGNORE INTO books(name, number) VALUES (?, ?)",
(book.name, book.number),
)
self.conn.commit()
return RepositoryResult.SUCCESS
except sqlite3.Error:
return RepositoryResult.FAILED
@dataclass
class SQLiteCharacterRepository(_SQLiteRepoBase, CharacterRepository):
db: Pathish | sqlite3.Connection
def __post_init__(self):
super().__init__(self.db)
def record(self, character: Character) -> RepositoryResult:
try:
self.conn.execute(
"INSERT OR IGNORE INTO characters(name) VALUES (?)",
(character.name,),
)
self.conn.commit()
return RepositoryResult.SUCCESS
except sqlite3.Error:
return RepositoryResult.FAILED
@dataclass
class SQLiteCharacterToBookMappingRepository(
_SQLiteRepoBase, CharacterToBookMappingRepository
):
db: Pathish | sqlite3.Connection
def __post_init__(self):
super().__init__(self.db)
def record(self, book: Book, character: Character) -> RepositoryResult:
try:
self.conn.execute(
"INSERT OR IGNORE INTO books(name, number) VALUES (?, ?)",
(book.name, book.number),
)
self.conn.execute(
"INSERT OR IGNORE INTO characters(name) VALUES (?)",
(character.name,),
)
self.conn.execute(
"""
INSERT OR IGNORE INTO character_book_mappings(book_id, character_id)
VALUES (
(SELECT id FROM books WHERE name=? AND number=?),
(SELECT id FROM characters WHERE name=?)
)
""",
(book.name, book.number, character.name),
)
self.conn.commit()
return RepositoryResult.SUCCESS
except sqlite3.Error:
return RepositoryResult.FAILEDWiring it together
A factory builds the right repositories for the chosen backend, and a service layer uses them without knowing which backend it got.
from __future__ import annotations
import sqlite3
from dataclasses import dataclass
from pathlib import Path
from typing import Callable, Literal
from discworld_cli.domain.repositories import (
BookRepository,
CharacterRepository,
CharacterToBookMappingRepository,
)
from discworld_cli.infrastructure.json.repositories import (
JSONFileBookRepository,
JSONFileCharacterRepository,
JSONFileCharacterToBookMappingRepository,
)
from discworld_cli.infrastructure.sqlite.repositories import (
SQLiteBookRepository,
SQLiteCharacterRepository,
SQLiteCharacterToBookMappingRepository,
)
Backend = Literal["sqlite", "json"]
@dataclass
class Repositories:
books: BookRepository
characters: CharacterRepository
mappings: CharacterToBookMappingRepository
close: Callable[[], None]
def make_repositories(
*,
backend: Backend,
sqlite_path: str | Path = "app.db",
json_dir: str | Path = "data",
) -> Repositories:
if backend == "sqlite":
conn = sqlite3.connect(sqlite_path)
return Repositories(
books=SQLiteBookRepository(db=conn),
characters=SQLiteCharacterRepository(db=conn),
mappings=SQLiteCharacterToBookMappingRepository(db=conn),
close=conn.close,
)
elif backend == "json":
base = Path(json_dir)
return Repositories(
books=JSONFileBookRepository(file_path=base / "books.json"),
characters=JSONFileCharacterRepository(file_path=base / "characters.json"),
mappings=JSONFileCharacterToBookMappingRepository(
file_path=base / "mappings.json"
),
close=lambda: None,
)
else:
raise ValueError(f"Unknown backend: {backend!r}")The catalogue service takes the abstract interfaces — never the concrete classes. Swapping backends means changing one argument to make_repositories and nothing else:
from __future__ import annotations
from discworld_cli.domain.models import Book, Character
from discworld_cli.domain.repositories import (
BookRepository,
CharacterRepository,
CharacterToBookMappingRepository,
RepositoryResult,
)
class CatalogService:
def __init__(
self,
books: BookRepository,
characters: CharacterRepository,
mappings: CharacterToBookMappingRepository,
) -> None:
self.books = books
self.characters = characters
self.mappings = mappings
def add_book(self, name: str, number: int) -> RepositoryResult:
return self.books.record(Book(name=name, number=number))
def add_character(self, name: str) -> RepositoryResult:
return self.characters.record(Character(name=name))
def map_character(
self, book_name: str, book_number: int, character_name: str
) -> RepositoryResult:
return self.mappings.record(
Book(name=book_name, number=book_number),
Character(name=character_name),
)The demo application
The full working implementation is open-source at sudoblark/sudoblark.patterns.repository-enterprise — a Typer CLI that persists Discworld characters and books to either JSON or SQLite, switchable with a single flag.

Have a read of the README and see how swapping backends with a feature flag looks in practice. Then lament at all the refactoring you want to do.
Conclusion
The monitoring platform migration that prompted all of this is done. DynamoDB is gone, Postgres is in, and Grafana is now the presentation layer. None of that required touching the business logic — the CatalogService didn’t move, the domain models didn’t move, and the only change visible to the rest of the application was the argument passed to make_repositories.
Not abstraction for its own sake, but the freedom to change your mind about infrastructure without unpicking the rest of the codebase. On a platform observing 8,000 builds a month and reporting to executive stakeholders, that was worth the upfront investment.
The Discworld CLI is a toy, but the structure it demonstrates is the same one running in production. Have a poke at sudoblark/sudoblark.patterns.repository-enterprise and see whether it prompts any refactoring of your own.
Further Reading:
- The Python Dictionary Dispatch Pattern — the pattern this replaced
- Patterns of Enterprise Application Architecture — Martin Fowler
- Repository pattern — Microsoft .NET Architecture Guide
- Python
abcmodule (official docs) - Python
sqlite3module (official docs) - sudoblark/sudoblark.patterns.repository-enterprise
Part 3 of 3 in Software Odds and Ends