Terraform with Data Structures and Algorithms

Part 1 of 3 in Sudoblark Best Practices
Introduction
This post is the first in the Sudoblark Best Practices series.
I once joined a data engineering project that had, conservatively, a hundred engineers working across it from multiple organisations. The systems engineering and infrastructure work had been contracted to a well-known consultancy. Their approach to Terraform was a Big Ball of Mud: one monolithic repository containing every single cloud resource, thousands of lines long, copy-pasted blocks everywhere.
Every time a data engineer needed a new AWS Lambda function or Glue job — which happened constantly on a project of that scale — they had to raise a ticket, wait for an infrastructure resource to find the time, and then watch as that resource manually translated requirements into HCL. The infrastructure team were working flat out and still falling behind. Releases went out once every two months on a good day, and failed more often than they shipped.
I knew I needed to build something different. The data engineering teams all used roughly the same set of AWS services — S3 buckets, Glue jobs, Lambda functions, Step Functions. If I could define a clean abstraction over those components, something with a known public interface that any engineer could interact with regardless of their Terraform knowledge, I could turn infrastructure from a bottleneck into a platform. Data engineers could self-service their own resources. The infrastructure team could focus on making the platform better rather than fulfilling individual tickets.
What I ended up building is what I now call the data-driven Terraform pattern. It applies data structures and algorithms — things that any engineer with a computer science background already understands — to the problem of infrastructure management. The result is Terraform that behaves like a proper software library: you supply a data structure conforming to a known interface, and the module handles the rest.
This post is the write-up of that pattern. It’s also been the subject of several conference talks, which is how I know it resonates — because the problems I’ve described above are not unique to that one project. I’ve seen variations of the same monolithic mess at multiple organisations, and the engineers who’ve heard these talks have recognised it immediately.
The goal
- Understand why monolithic Terraform codebases become a bottleneck for the whole engineering team
- See how applying data structures and algorithms to Terraform modules enables self-service infrastructure
- Follow a complete module implementation from interface definition through to resource creation
- Understand the unified index pattern and why it keeps module internals coherent at scale
- Know the trade-offs — versioning overhead, the suffix trap, the onboarding curve — before adopting it
Prerequisites
- Familiarity with Terraform basics: variables, resources, and modules
- Some exposure to AWS services (Lambda, S3, Step Functions) — the patterns apply elsewhere, but the examples are AWS
- Basic comfort with data structures (lists and maps/dictionaries)
The Problem
Infrastructure-as-Code promised us a single source of truth for our infrastructure. Terraform, in particular, made that promise feel achievable — declarative, reproducible, version-controlled. So why do so many Terraform codebases end up as the opposite?
The short answer is that Terraform gets treated as a configuration language rather than a programming language. Teams write resource blocks for every individual thing they need, copy-paste them when they need more, and end up with files that run to thousands of lines. There’s no abstraction, no reuse, no separation of concerns. The Big Ball of Mud paper describes this as a system that “grows by accretion” — each addition is locally rational but globally incoherent.
The loss of the single source of truth is the most visible symptom. When you have twenty variations of the same Lambda module hand-written across a codebase, you don’t have one definition of a Lambda — you have twenty, each slightly different, each maintained independently. The moment you need to change something (a tagging policy, a logging configuration, a security group rule), you’re doing it twenty times and hoping you don’t miss one.
But the subtler cost is what it does to the rest of the engineering team. Terraform is a programming language in structure — it has variables, locals, functions, conditionals, loops — but when it’s used purely as a wishlist of resources, none of those features get used. You get all the baggage of a programming language (state management, provider versioning, plan/apply cycles) with none of the benefits. Extensibility, reuse, and abstraction are replaced by closely-coupled code and copy-paste.
The deepest problem is this:
Infrastructure is only useful when it fulfils a business need, that need is often encapsulated in some form of application code, and business needs — as we all know — are liable to change on a whim.
When infrastructure and application code are tangled together in a single monolithic repository, every change to one affects the other. Application engineers can’t follow their own best practices — unit tests, fast iteration, feature branches — because the deployment mechanism is too slow and too fragile. Infrastructure engineers become ticket-takers rather than platform builders. And the release cadence reflects it.
On that data engineering project, before I changed anything, the team shipped once every two months — a release cadence driven entirely by infrastructure friction, not by the pace of development.
The Pattern
Terraform modules already accept variables. If you design those variables as structured collections — lists of objects — then consuming a module becomes a data manipulation problem rather than a Terraform problem. Add items to the list to create resources. Mutate items to change them. Remove items to destroy them. That’s CRUD, and every engineer already understands CRUD.
The pattern has two perspectives: what it looks like for the person consuming a module, and what’s required to build one correctly.
What the user sees
From a user’s perspective, interacting with a well-designed module requires no Terraform knowledge whatsoever. They never need to understand for_each, depends_on, provider configuration, or state. What they need to understand is the module’s public interface — the shape of the data structure it accepts — and then they manipulate that data structure to get the infrastructure they want.
The examples below draw from the data-driven pattern as originally implemented across Sudoblark’s modules. Sudoblark has since migrated to the three-tier Terraform data pattern for most modules due to the scale of the platform — but the underlying DSA principles are identical. Code is shown in full; links to specific module repositories have been omitted where they no longer reflect the original structure.
The entire user interface for an S3 file upload module is a single variable:
variable "raw_s3_files" {
description = <<EOT
Data structure
---------------
A list of dictionaries, where each dictionary has the following attributes:
REQUIRED
---------
- name: : Friendly name used through Terraform for instantiation and cross-referencing of resources,
only relates to resource naming within the module.
- source_folder : Which folder where the {source_file} lives.
- source_file : The path under {source_folder} corresponding to the file to upload.
- destination_key : Key in S3 bucket to upload to.
- destination_bucket : The S3 bucket to upload the {source_file} to.
OPTIONAL
---------
- template_input : A dictionary of variable input for the template file needed for instantiation (leave blank if no template required)
EOT
type = list(
object({
name = string,
source_folder = string,
source_file = string,
destination_key = string,
destination_bucket = string,
template_input = optional(map(string), {})
})
)
}To upload three files, you pass a list with three items. To stop uploading one of them, you remove it. To change a destination bucket, you edit the relevant item. The module takes care of everything else — IAM permissions, resource naming, state management. The user never touches any of it.
This is the abstraction. Infrastructure engineers build the platform once. Everyone else uses it.
What the developer must build
Building a module that delivers this experience requires four things done properly.
A documented public interface
The contract between module and consumer must be explicit. The multi-line description block in variables.tf is the minimum viable approach — document required fields, optional fields, constraints, and any contextual dependencies the module has (IAM roles, existing VPCs, etc.). For larger platforms, tools like mkdocs can generate browsable documentation that mirrors the Hashicorp registry experience. The format matters less than the commitment to maintaining it. An undocumented interface is no interface at all.
A mutable collection as the input type
The variable type must be list(object({...})) — not a scalar, not a single object. This is what enables the CRUD semantics. Terraform’s optional() syntax (available since 0.14) lets you make fields optional with defaults, which keeps the interface clean for common cases without sacrificing flexibility for edge cases.
A unified index
This is the piece that makes the pattern work at scale, and the one that took me the longest to articulate clearly. Every item in the input list needs a field — I use suffix — that acts as a stable, human-readable key for that conceptual resource. The module then uses that key consistently across every resource it creates internally.
A single module call might create five or six AWS resources per item in the list: the primary resource, an IAM role, a policy document, a log group, maybe a security group. All of those resources need to reference each other. Without a unified index, you end up using integer-based indexing (var.raw_items[0]), which breaks the moment anyone reorders the list. With a suffix-based index, relationships are stable regardless of list order, and your Terraform state becomes legible — module.step_function_state_machine["my-etl-job"] rather than module.step_function_state_machine[0].
Look at how the suffix threads through the state machine module. In aws_iam_policy_document.tf, every policy document is keyed by suffix:
locals {
actual_iam_policy_documents = {
for state_machine in var.raw_state_machines :
state_machine.suffix => {
statements = concat(state_machine.iam_policy_statements, local.barebones_statemachine_statements,
[
{
sid = "ListOwnExecutions",
actions = ["states:ListExecutions"]
resources = [
format(
"arn:aws:states:%s:%s:stateMachine:%s-%s-%s-stepfunction",
lower(data.aws_region.current_region.name),
lower(data.aws_caller_identity.current_account.id),
lower(var.environment),
lower(var.application_name),
lower(state_machine.suffix)
)
]
conditions = []
}
]
)
}
}
}
data "aws_iam_policy_document" "attached_policies" {
for_each = local.actual_iam_policy_documents
...
}Then in state_machine.tf, that same suffix is used to look up the correct policy for each state machine — no integer indexing, no ambiguity:
locals {
actual_state_machines = {
for state_machine in var.raw_state_machines :
state_machine.suffix => merge(state_machine, {
state_machine_definition = templatefile(state_machine.template_file, state_machine.template_input)
policy_json = data.aws_iam_policy_document.attached_policies[state_machine.suffix].json
state_machine_name = format("%s-%s-%s-stepfunction", var.environment, var.application_name, state_machine.suffix)
})
}
}Elegant implementation code
The user-facing interface is only half the job. Someone — probably you, six months later — will need to extend or debug the module. Splitting files by concern (variables.tf, common_iam_policies.tf, aws_iam_policy_document.tf, state_machine.tf) keeps each file focused and short. The iteration pattern is uniform throughout: always a for expression over the input list, always keyed by suffix. There’s no cognitive overhead switching between files because the structure is always the same.
The full variables.tf for the state machine module shows how interface definition, type enforcement, and input validation combine:
variables.tf — interface definition and input validation
variable "environment" {
description = "Which environment this is being instantiated in."
type = string
validation {
condition = contains(["dev", "test", "prod"], var.environment)
error_message = "Must be either dev, test or prod"
}
}
variable "application_name" {
description = "Name of the application utilising resource."
type = string
}
variable "raw_state_machines" {
description = <<EOF
Data structure
---------------
A list of dictionaries, where each dictionary has the following attributes:
REQUIRED
---------
- template_file : File path which this machine corresponds to
- template_input : A dictionary of key/value pairs, outlining inputs needed for a template to be instantiated
- suffix : Friendly name for the state function
- iam_policy_statements : A list of dictionaries where each dictionary is an IAM statement defining permissions
-- Each dictionary must define:
--- sid: Friendly name for the policy, no spaces or special characters
--- actions: A list of IAM actions the state machine is allowed to perform
--- resources: Which resource(s) the state machine may perform the above actions against
--- conditions : An OPTIONAL list of dictionaries, each defining:
---- test : Test condition for limiting the action
---- variable : Value to test
---- values : A list of strings, denoting what to test for
OPTIONAL
---------
- cloudwatch_retention : How many days logs should be retained in Cloudwatch, defaults to 90
EOF
type = list(
object({
template_file = string,
template_input = map(string),
suffix = string,
iam_policy_statements = list(
object({
sid = string,
actions = list(string),
resources = list(string),
conditions = optional(list(
object({
test : string,
variable : string,
values = list(string)
})
), [])
})
),
cloudwatch_retention = optional(number, 90)
})
)
validation {
condition = alltrue([
for state_machine in var.raw_state_machines : (tonumber(state_machine.cloudwatch_retention) >= 0)
])
error_message = "cloudwatch_retention for each state machine should be a valid integer greater than or equal to 0"
}
}Implementing Architectures
The pattern scales to two structural approaches depending on what you’re building.
Re-usable components with downstream consumers
The first approach separates module repositories from consumer repositories. Each module lives in its own repository and exposes a single data structure interface for a single conceptual resource type — state machines, Lambda functions, S3 uploads, whatever. Consumer repositories then pull in whichever modules they need and compose them to build the actual product.
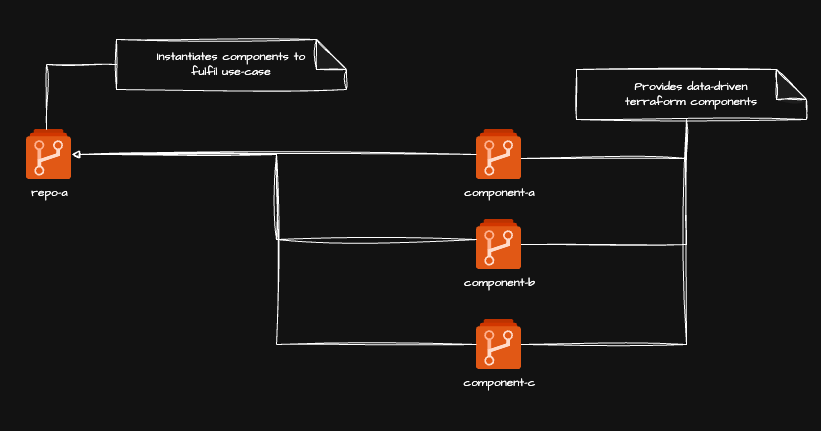
Each module repository defines a single Terraform module accepting the data structure interface described above. A consumer repository instantiates whichever modules it needs, supplying the appropriate data structures to drive resource creation. The consumer never writes raw resource blocks — it only manages data.
The advantage of this structure is genuine reusability across projects and teams. Fix a bug in a module and every consumer gets the fix when they update their version pin. Add a feature and consumers opt in at their own pace. The version contract protects both sides.
That protection pays off when you have the structure to benefit from it: a dedicated infrastructure engineering team maintaining modules as a product, and multiple application teams consuming them. The version pin is a real boundary between two groups of people with different concerns and different release cadences.
A related pattern for different circumstances
Where the versioned-module approach starts to strain is when you’re both teams. The maintenance overhead of tagging, publishing, and bumping version pins across consumer repositories adds up quickly — and if there’s only one person or a small team doing all of it, the ceremony starts to outweigh the benefit.
That’s the context in which I developed the three-tier Terraform data pattern: it applies the same DSA foundations but uses local modules within a single repository instead of versioned remote ones, eliminating the release engineering overhead at the cost of cross-project reusability. Neither pattern supersedes the other — they serve different circumstances.
If you’re a larger organisation with a dedicated infrastructure platform team serving multiple consumer teams, the versioned-module approach described in this post is the right call. If you’re a smaller team maintaining both the modules and the data structures yourself, the three-tier post covers the trade-offs in detail.
What it looks like in practice
On that data engineering project I described at the start, I built the first version of this pattern under real production pressure. The data engineering teams were all using the same four or five AWS services. I modularised each of them, defined the interfaces, and gave the teams a platform they could self-service through data structures. They didn’t need to understand Terraform. They needed to understand a list of dictionaries.
The result was a shift from one release every two months — often failing — to a peak of twelve releases per day. Infrastructure stopped being the bottleneck and became a force multiplier. The teams could focus entirely on the business logic that mattered to the project, because the plumbing was handled.
That enterprise subsequently adopted the pattern as an internal standard. I’ve since seen them give conference talks about it. They don’t mention the consultancy engagement that originated it, but I know where it came from — and watching a pattern you invented spread through an organisation until it becomes their default way of working is one of the more satisfying things that can happen in this profession.
Production Considerations
The data-driven pattern works. But it asks real things of the teams that adopt it.
Module versioning overhead
When modules live in separate repositories, every consumer needs to pin a version. That’s the right call — you don’t want an upstream change breaking production infrastructure without warning — but it creates a maintenance burden. If you have twenty consumer repositories all pinning the state machine module at v1.2.0, rolling out a new version means opening twenty pull requests.
There are ways to reduce this friction — automated dependency update tools like Renovate handle the PR churn reasonably well — but the overhead is worth accounting for before committing to the multi-repo structure.
The suffix trap
The unified index that makes the pattern so readable is also its sharpest edge. If you rename a suffix value — even to fix a typo — Terraform interprets it as destroy-and-recreate. The old resource disappears from state and a new one is created in its place. For stateless resources that’s inconvenient. For an RDS instance or a Step Functions state machine with execution history, it can be serious.
The fix is Terraform’s moved block, which tells the state engine that a resource has been renamed rather than replaced:
moved {
from = module.step_function_state_machine["old-suffix"]
to = module.step_function_state_machine["new-suffix"]
}Treat suffix values as permanent identifiers from the moment you apply them. If you must change one, use moved.
The onboarding curve
Almost no one works this way when they first encounter it. Engineers coming from conventional Terraform backgrounds find the for expression pattern unfamiliar at first. The abstraction layer is clean once you understand it, but that understanding has to be built.
A well-written README explaining the pattern, with a worked example of adding and removing a resource, does most of the heavy lifting. I’ve given talks on this at several conferences now, and the consistent feedback is that once it clicks, people wonder how they worked any other way — but the click has to happen first. Don’t assume it’s obvious.
Conclusion
This pattern came from a real problem: infrastructure as a bottleneck, a monolithic codebase nobody fully understood, and application engineers who couldn’t move at the pace the project required.
What I’ve described here is that abstraction in its original form: Terraform modules designed around data structures, consumed through a known public interface, with a unified index threading through everything the module creates. It asks the infrastructure engineer to invest upfront in module quality. In return, it gives the whole team velocity and autonomy.
The results speak for themselves. Twelve releases per day from a team that was shipping once every two months. Infrastructure that application engineers could change without raising tickets. A codebase legible enough that a new hire could add a resource without needing a guided tour.
The pattern comes with trade-offs — versioning overhead, the suffix trap, an onboarding curve for engineers new to it. And there are circumstances where a different approach is the better call, which is what the three-tier post is about. But for a mid-to-large engineering organisation with a dedicated infrastructure platform function, this is the pattern I’d reach for. It has been, consistently, across multiple engagements.
Further Reading:
- The Three-Tier Terraform Data Pattern — a related pattern built on the same DSA foundations, suited to smaller teams and solo work where versioned-module overhead isn’t justified
- sudoblark.terraform.modularised-demo — a working demo ETL pipeline built with this pattern
- sudoblark.monsternames.api — a live REST API whose infrastructure is entirely data-driven
- Big Ball of Mud — Foote & Yoder’s original paper; still the best description of how large codebases decay
- What is CRUD? — Codecademy’s primer on CRUD operations, referenced in the pattern section
Part 1 of 3 in Sudoblark Best Practices