Rebuilding the Bookshelf: Replacing the Manual Bedrock Chain with pydantic-ai

Part 2 of 3 in AI Vision Inference
Introduction
This post is part of the AI Vision Inference series, which uses a bookshelf scanner as the running problem domain to explore serverless AI inference on AWS. The idea is simple: you upload a ZIP of book cover images, and the pipeline extracts structured metadata — title, author, ISBN, publisher, year — queryable via SQL. S3 events trigger Lambda functions, Lambda calls AWS Bedrock (Claude 3 Haiku) to do the vision inference, Pydantic validates the response, and results land in Parquet files in S3 for Athena to query. The first post in the series covers that architecture in full.
This post is about what the implementation actually looked like when I wrote that architecture post — and what I’ve since done about it. The Lambda worked. The architecture post is still accurate. But the code was coupled to Bedrock’s API surface at every level, and I knew before publishing that I’d need to fix it before building further on top of it.
The Lambda function doing the metadata extraction was 508 lines long. Not because the problem is hard — the actual logic is compact. It was 508 lines because everything was hand-rolled: base64 encoding the image, constructing the Bedrock API payload manually, parsing the raw JSON response with two fallback strategies, and finally applying Pydantic validation as a cleanup step at the very end. Four distinct stages, each requiring its own error handling, none of which benefited from the type system until the last one.
The refactor (release 1.1.0) replaces that chain with a pydantic_ai.Agent[None, BookMetadata]. Simpler code is the side effect. The primary purpose is decoupling: where the old code was coupled to Bedrock’s specific API surface at every level, the pydantic-ai Agent abstracts all of that behind one interface. That makes swapping providers trivial, makes silent failures explicit, and — crucially — opens up tool integration. That’s where this series is heading.
The goal
- Show what the manual Bedrock invocation chain looked like and why it was tightly coupled to Bedrock’s API
- Explain what pydantic-ai’s Agent changes: decoupling from platform-specific code and making
BookMetadatathe AI output contract rather than a post-processing cleanup step - Cover the module split: what the 508-line monolith became
- Explain how the Agent primitive enables tool integration — what a chain of function calls can never do cleanly
- Cover the packaging constraint that catches teams by surprise: staying under Lambda’s 262 MB uncompressed limit
Prerequisites
Familiarity with Python, Pydantic, and basic AWS Lambda patterns is enough to follow this post. The previous post isn’t required reading — the relevant context is summarised above and inline where needed. The full picture of the event-driven architecture this Lambda sits inside is in Event-Driven Vision Inference with Bedrock, Pydantic, and Parquet.
Python & AWS Lambda
Where Things Stood
The old lambda_function.py had a function called extract_metadata_with_bedrock. Here’s what it did, step by step.
Step 1: Resize the image and base64-encode it
resized_image_bytes: bytes = resize_image_to_jpeg(image_bytes, max_dim=1024)
image_base64: str = base64.b64encode(resized_image_bytes).decode("utf-8")Step 2: Build the Bedrock API payload manually
request_body: Dict[str, Any] = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": image_base64,
},
},
{"type": "text", "text": METADATA_EXTRACTION_PROMPT},
],
}
],
}Step 3: Call invoke_model and parse the raw JSON response
response = bedrock_client.invoke_model(modelId=model_id, body=json.dumps(request_body))
response_body: Dict[str, Any] = json.loads(response["body"].read())
response_text: str = response_body["content"][0]["text"]Step 4: Parse the text into something Pydantic can validate
This is where it got awkward. The prompt said ONLY a valid JSON object — no markdown, no code blocks, no explanation text, but prompt + hope isn’t a strategy. So parse_bedrock_response had three approaches:
def parse_bedrock_response(response_text: str) -> Dict[str, Any]:
try:
# Strategy 1: parse the response directly as JSON
parsed = json.loads(response_text.strip())
validated = BookMetadata(**parsed)
return validated.model_dump()
except json.JSONDecodeError:
try:
# Strategy 2: find the JSON object buried in surrounding text
start = response_text.find("{")
end = response_text.rfind("}") + 1
if start >= 0 and end > start:
validated = BookMetadata(**json.loads(response_text[start:end]))
return validated.model_dump()
except (json.JSONDecodeError, ValueError):
pass
# Strategy 3: give up and return empty defaults
return BookMetadata().model_dump()That third strategy — silent fallback to an empty BookMetadata — is the uncomfortable part. If parsing failed entirely, the result was a Parquet record with no title, no author, no ISBN. No exception. No retry. The S3 event was consumed successfully from Lambda’s perspective, and a record full of empty strings landed in the analytics layer. The failure would only surface when querying the data downstream.
Each of the four steps could fail independently: base64.b64encode on corrupt image data, invoke_model on a Bedrock throttle, json.loads on a malformed response body, validation on a type mismatch. And each failure mode required separate error handling wrapped around it.
Enter pydantic-ai
pydantic-ai is a Python framework for building AI agents with Pydantic at the core. The primitive that matters here is Agent[None, BookMetadata]:
from pydantic_ai import Agent, BinaryContent
from pydantic_ai.models.bedrock import BedrockConverseModel
from pydantic_ai.providers.bedrock import BedrockProvider
provider = BedrockProvider(bedrock_client=client)
model = BedrockConverseModel(model_id, provider=provider)
self._agent: Agent[None, BookMetadata] = Agent(
model,
output_type=BookMetadata,
system_prompt=SYSTEM_PROMPT,
)Calling agent.run_sync(...) handles Bedrock serialisation, manages the API call, deserialises the response, and retries if the model returns something that doesn’t satisfy the BookMetadata schema. result.output is already a typed BookMetadata — not raw text, not a dictionary. Here’s the resulting extract method from bedrock_extractor.py:
def extract(self, image_bytes: bytes, filename: str) -> Dict[str, Any]:
if not image_bytes:
raise ValueError("image_bytes must not be empty")
resized: bytes = ImageProcessor.resize_to_jpeg(image_bytes)
result = self._agent.run_sync(
[
"Extract the book metadata from this cover image.",
BinaryContent(data=resized, media_type="image/jpeg"),
]
)
metadata: Dict[str, Any] = result.output.model_dump()
return self._apply_defaults(metadata, filename)The four-step chain is gone. BinaryContent handles the image encoding. run_sync handles the API call and response parsing. result.output is already validated. The fallback parsing strategies aren’t needed because the agent retries until it gets a valid BookMetadata or raises an exception — The exception propagates rather than being swallowed into empty defaults — it can be caught, logged, and surfaced explicitly.
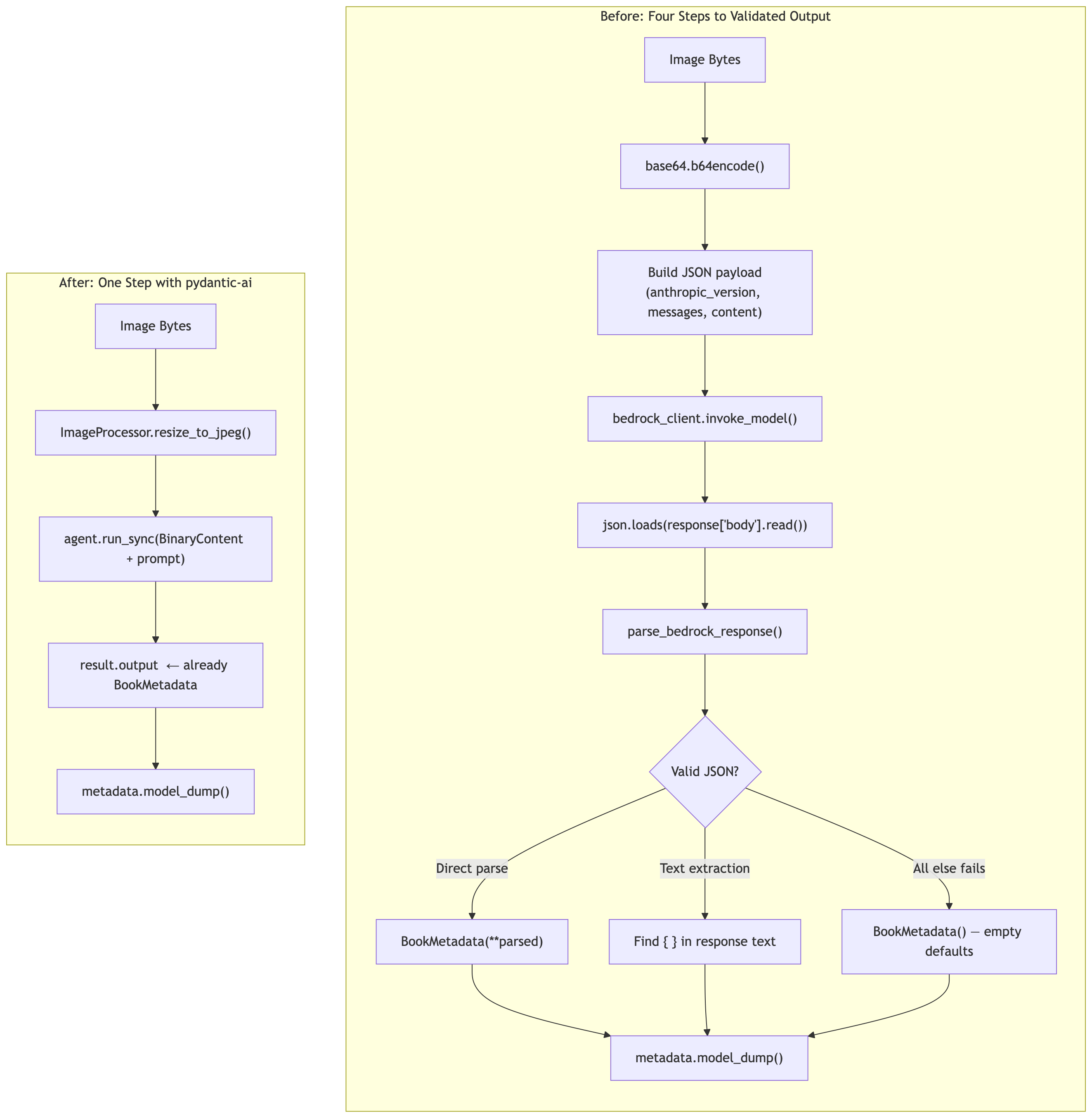
flowchart BT
subgraph before ["Before: Four Steps to Validated Output"]
A1["Image Bytes"] --> B1["base64.b64encode()"]
B1 --> C1["Build JSON payload\n(anthropic_version, messages, content)"]
C1 --> D1["bedrock_client.invoke_model()"]
D1 --> E1["json.loads(response['body'].read())"]
E1 --> F1["parse_bedrock_response()"]
F1 --> G1{Valid JSON?}
G1 -->|Direct parse| H1["BookMetadata(**parsed)"]
G1 -->|Text extraction| I1["Find { } in response text"]
G1 -->|All else fails| J1["BookMetadata() — empty defaults"]
H1 --> K1["metadata.model_dump()"]
I1 --> K1
J1 --> K1
end
subgraph after ["After: One Step with pydantic-ai"]
A2["Image Bytes"] --> B2["ImageProcessor.resize_to_jpeg()"]
B2 --> C2["agent.run_sync(BinaryContent + prompt)"]
C2 --> D2["result.output ← already BookMetadata"]
D2 --> E2["metadata.model_dump()"]
endSplitting the Monolith
The refactor didn’t just swap the Bedrock invocation. It broke lambda_function.py apart into focused modules:
| Module | Class / entry point | Responsibility |
|---|---|---|
bedrock_extractor.py | BedrockMetadataExtractor | Wraps the pydantic-ai Agent |
models.py | BookMetadata | Pydantic model with validators |
image_processor.py | ImageProcessor.resize_to_jpeg() | Image pre-processing only |
parquet_writer.py | ParquetWriter | S3 Parquet persistence |
processor.py | BookshelfProcessor | Orchestrates the pipeline |
config.py | Config.from_env() | Environment variable handling |
lambda_function.py | handler | Handler wiring, ~63 lines |
The old lambda_function.py was monolithic because the boundaries didn’t exist. Config loading, image resizing, Bedrock calls, JSON parsing, S3 operations, and Parquet writing all lived in the same file. Testing any one piece meant either mocking everything around it or running against real AWS.
Now each class has a single job. ImageProcessor only resizes images. ParquetWriter only writes Parquet. BedrockMetadataExtractor only calls the Agent. BookshelfProcessor orchestrates them. The orchestrator is the most illustrative — it contains no AI-specific logic whatsoever:
class BookshelfProcessor:
def __init__(self, config: Config, s3_client: Any, bedrock_client: Any) -> None:
self._config = config
self._s3_client = s3_client
self._extractor = BedrockMetadataExtractor(config.bedrock_model_id, bedrock_client)
self._writer = ParquetWriter(s3_client)
def process(self, source_bucket: str, image_key: str) -> str:
processed_bucket: str = self._resolve_processed_bucket(source_bucket)
image_obj = self._s3_client.get_object(Bucket=source_bucket, Key=image_key)
image_bytes: bytes = image_obj["Body"].read()
metadata: Dict[str, Any] = self._extractor.extract(image_bytes, image_key)
parquet_key: str = self._writer.write(metadata, processed_bucket)
return parquet_keyDownload, extract, write. BookshelfProcessor doesn’t know about base64, API payloads, or Parquet serialisation. This is the Single Responsibility Principle in practice: each class owns one concern, and the orchestrator’s only job is to sequence them. When ParquetWriter changes — say, switching from in-memory buffering to streaming writes — BookshelfProcessor doesn’t change at all. The blast radius of any modification is contained to the class that owns that concern.
The Validation Story
models.py now lives on its own:
from pydantic import BaseModel, Field, field_validator
from typing import Optional
class BookMetadata(BaseModel):
title: str = Field(default="", description="Book title")
author: str = Field(default="", description="Author name(s)")
isbn: str = Field(default="", description="ISBN (digits only, no hyphens)")
publisher: str = Field(default="", description="Publisher name")
published_year: Optional[int] = Field(default=None, description="Year of publication")
description: str = Field(default="", description="Brief book description")
confidence: Optional[float] = Field(
default=None,
ge=0.0,
le=1.0,
description="AI extraction confidence (0.0-1.0)",
)
@field_validator("isbn")
@classmethod
def validate_isbn(cls, v: str) -> str:
"""Remove hyphens and spaces from ISBN."""
if v:
return v.replace("-", "").replace(" ", "")
return v
@field_validator("published_year")
@classmethod
def validate_year(cls, v: Optional[int]) -> Optional[int]:
"""Validate year is reasonable."""
if v is not None and (v < 1000 or v > 2100):
return None
return vIn the old code, BookMetadata was a cleanup step — instantiated at the end of a manually-parsed response, after three fallback strategies had been attempted. If parsing failed entirely, BookMetadata() was called with no arguments and silently produced empty defaults. The model was downstream validation applied to whatever text came back.
With output_type=BookMetadata, the schema becomes the AI’s output contract. pydantic-ai sends the schema to Bedrock, which produces structured output aligned to it. If the response doesn’t satisfy the schema, the agent retries rather than falling back to empty defaults. BookMetadata is no longer a filter applied after extraction; it’s the requirement the extraction must satisfy. The three-strategy fallback parser existed because the old code couldn’t enforce the contract — it could only ask nicely in the prompt and handle whatever came back. The framework enforces it structurally.
Packaging Under the Limit
Lambda has a deployment package size limit: 50 MB for direct upload, 262 MB uncompressed when using layers. The metadata extractor relies on three heavy dependencies — pandas, pyarrow, and aws-lambda-powertools — all of which are available as Lambda layers. The AWS SDK for Pandas layer covers pandas and pyarrow; Powertools has its own.
The deployment ZIP must not bundle them. The requirements.txt now explicitly excludes everything provided by the runtime or layers:
# Lambda runtime dependencies (deployment)
# Exclude: boto3 (provided by Lambda runtime), pandas/pyarrow (in AWS SDK for Pandas layer),
# aws-lambda-powertools (provided by the AWS Lambda Powertools layer)
# pydantic-ai-slim[bedrock] includes only the core framework and the boto3-backed
# BedrockConverseModel provider. Avoids bundling unused provider SDKs (Anthropic,
# OpenAI, Google, etc.) that would push the ZIP over Lambda's 50 MB direct-upload limit.
Pillow
pydantic
pydantic-ai-slim[bedrock]pydantic-ai-slim[bedrock] is worth noting specifically. The full pydantic-ai package includes client SDKs for Anthropic, OpenAI, Google, and others. None of those are needed here — Bedrock is accessed via boto3, which the Lambda runtime already provides. pydantic-ai-slim is the framework without the bundled provider SDKs. BedrockConverseModel and BedrockProvider are included without dragging in the Anthropic SDK, which alone would push the package size over the limit.
Lambda deployment packages and CI test environments have different dependency requirements, and conflating them causes problems in both directions. The deployment package must be as small as possible — every included package counts against the 262 MB limit, and anything provided by a Lambda layer (Powertools, pandas, pyarrow) should be excluded. The CI environment, on the other hand, needs those same layer-provided packages installed locally so tests can import them.
The pattern is two requirements files: requirements.txt for the deployment package (layer-provided packages excluded), and requirements-ci.txt which extends it with everything needed to run tests. CI installs from requirements-ci.txt; the deployment ZIP is built from requirements.txt only. The split is worth documenting explicitly in both files — future maintainers need to know why a package appears in one but not the other, or they’ll “fix” it by adding it to requirements.txt and wonder why the deployment suddenly exceeds the size limit.
The failure message — Unzipped size must be smaller than 262144000 bytes — surfaces during deployment, not locally. I’ve learned to check the uncompressed package size as part of the build step rather than waiting for a CI pipeline to tell me about it.
Testing Gets Cleaner
The previous test suite required careful boto3 mocking for anything touching the Bedrock invocation chain: constructing fake response objects, stubbing Body.read() return values, and mimicking the payload structure the code expected. pydantic-ai ships with a TestModel that replaces all of that:
from pydantic_ai.models.test import TestModel
def test_extract_returns_metadata_with_defaults(self):
extractor = self._make_extractor()
img_buffer = io.BytesIO()
Image.new("RGB", (100, 100), color="red").save(img_buffer, format="JPEG")
with extractor._agent.override(
model=TestModel(
custom_output_args={
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"isbn": "9780743273565",
"publisher": "Scribner",
"published_year": 1925,
"description": "A classic novel.",
"confidence": 0.95,
}
)
):
result = extractor.extract(img_buffer.getvalue(), "test.jpg")
assert result["title"] == "The Great Gatsby"
assert result["filename"] == "test.jpg"
assert "id" in result
assert "processed_at" in resultNo boto3 mocking. No constructing fake API response payloads. TestModel accepts the expected BookMetadata fields and the agent produces a validated instance. The test covers the actual logic: image resizing, metadata extraction, and default field population (id, filename, processed_at).
Testing failure modes is equally direct. FunctionModel accepts a custom function to inject arbitrary behaviour:
from pydantic_ai.models.function import AgentInfo, FunctionModel
from pydantic_ai.messages import ModelMessage
from pydantic_ai import UnexpectedModelBehavior
def test_extract_model_failure_propagates(self):
extractor = self._make_extractor()
img_buffer = io.BytesIO()
Image.new("RGB", (100, 100), color="red").save(img_buffer, format="JPEG")
def failing_model(messages: list[ModelMessage], info: AgentInfo) -> None:
raise UnexpectedModelBehavior("Model unavailable")
with extractor._agent.override(model=FunctionModel(failing_model)):
with pytest.raises(Exception):
extractor.extract(img_buffer.getvalue(), "test.jpg")Full exceptions, partial responses, malformed outputs — all of it is testable without a real Bedrock endpoint or a fragile mock setup. The test is also honest: it asserts that the exception propagates, which is the correct behaviour. No silent fallback to empty defaults.
Production Considerations
Cost
Bedrock charges per input and output token. Claude 3 Haiku’s pricing is low — roughly 0.00125 per 1,000 output tokens — but multimodal requests cost more than text-only ones because image content is tokenised differently. A resized 1024×1024 JPEG typically consumes around 1,600 input tokens for the image alone, before the system prompt and extraction prompt are added. Across 10,000 book covers that works out to roughly $4–6 in input tokens, plus a fraction of that for output. At workshop scale that’s negligible; at production scale with continuous ingestion it’s worth monitoring.
pydantic-ai’s retry mechanism is the main cost multiplier to be aware of. By default the Agent retries once if the model returns a response that fails schema validation. A retry is a full Bedrock invocation — same token cost, same latency. Raising the retries parameter increases robustness but also increases worst-case cost. I’ve left the default for the bookshelf demo since Haiku’s structured output is reliable at this schema complexity, but for more demanding schemas it’s worth tuning explicitly.
Performance
Lambda cold starts are the dominant latency factor for infrequently-invoked functions. Adding pydantic-ai-slim to the deployment package increases import time on cold start — in my testing, roughly 300–500 ms additional init duration compared to the raw boto3 invocation chain. For the bookshelf demo’s S3-triggered pattern this is acceptable; the pipeline is throughput-bound, not latency-bound. For latency-sensitive applications, keeping the package footprint small (which pydantic-ai-slim already helps with) and considering provisioned concurrency are the main levers.
The pydantic-ai Agent’s retry loop also adds latency on validation failure. In practice this is rare with Haiku at BookMetadata’s schema complexity, but it’s a tail-case worth accounting for in timeout configuration. I set the Lambda timeout to 60 seconds, which comfortably covers two inference round-trips with room for image resizing and S3 I/O.
Security
The Lambda execution role needs bedrock:InvokeModel permission scoped to the specific model ARN rather than a wildcard. The Terraform for this series uses:
resource "aws_iam_role_policy" "bedrock_invoke" {
role = aws_iam_role.lambda_exec.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Effect = "Allow"
Action = ["bedrock:InvokeModel"]
Resource = "arn:aws:bedrock:${var.region}::foundation-model/anthropic.claude-3-haiku-20240307-v1:0"
}]
})
}The image_bytes input to BedrockMetadataExtractor.extract is validated for emptiness before any resizing or API call, which prevents sending a zero-byte payload to Bedrock. Book cover images are unlikely to contain PII, but if this pattern were adapted to documents that do, the input validation boundary is the right place to add content filtering before data leaves the AWS account boundary.
Observability
AWS Lambda Powertools is already in the runtime environment via the managed layer. The existing lambda_function.py uses the Powertools Logger for structured JSON logging. Adding the Tracer to BedrockMetadataExtractor gives X-Ray traces for Bedrock invocation latency and retry counts with minimal overhead:
from aws_lambda_powertools import Tracer
tracer = Tracer()
class BedrockMetadataExtractor:
@tracer.capture_method
def extract(self, image_bytes: bytes, filename: str) -> Dict[str, Any]:
...The two metrics worth capturing explicitly are Bedrock invocation count (to track retry rate) and extraction latency per image — both are derivable from X-Ray traces without adding custom metric instrumentation.
What This Unlocks
The pydantic-ai Agent is a foundation, not just a replacement. The refactor as described delivers structured output, automatic retry on validation failure, and clean testing. But the Agent primitive is designed for more.
Right now BedrockMetadataExtractor does one thing: call the model and return validated metadata. If the application later needed to look up ISBNs against an external catalogue to fill in missing data, that’s a tool:
@self._agent.tool
async def lookup_isbn(ctx: RunContext, isbn: str) -> str:
"""Look up book details from an external catalogue."""
# call an ISBN lookup API, return enriched metadata
...The agent decides when to call it, incorporates the result into the conversation, and continues until it produces a valid BookMetadata. The extraction pipeline doesn’t change — a tool gets registered. That’s the structural difference between a framework and a chain of function calls: the chain requires a rewrite; the framework requires an addition.
This is just the start. Future posts in the AI Vision Inference series will build out a rich ecosystem of tools for the agent — enriching extracted metadata from external sources, cross-referencing ISBNs, and more. The refactor here lays the groundwork that makes all of that possible.
Platform Interoperability
All the code in this series runs on AWS: Lambda, Bedrock, S3. That’s what I know best and what the bookshelf demo uses. But the patterns here aren’t AWS-specific, and it’s worth being explicit about where the boundaries sit.
The pydantic-ai Agent is the key abstraction. It accepts a model at construction time, and pydantic-ai ships with provider implementations for all the major platforms:
| Platform | Model class | Provider |
|---|---|---|
| AWS | BedrockConverseModel | BedrockProvider(bedrock_client=client) |
| GCP | VertexAIModel | VertexAIProvider(...) |
| Azure | OpenAIModel with Azure endpoint | OpenAIProvider(base_url=azure_endpoint, api_key=...) |
| On-prem | OpenAIModel with Ollama endpoint | OpenAIProvider(base_url="http://localhost:11434/v1", api_key="ollama") |
Swapping providers is a construction-time change in BedrockMetadataExtractor.__init__. The extract method, the BookMetadata schema, the validators, the tests — none of that changes. The agent’s contract with the rest of the codebase is output_type=BookMetadata. That contract holds regardless of which model backs it.
The compute layer follows the same logic. Lambda is the function runtime used here. Cloud Functions (GCP), Azure Functions, and on-prem Kubernetes jobs all expose the same model: an event triggers a function, the function runs to completion and exits. The handler signature differs, but the pattern of “S3 event → download image → extract metadata → write output” maps directly:
- GCP: Cloud Storage trigger on Cloud Functions, Vertex AI in place of Bedrock, BigQuery or Cloud Storage + Dataproc in place of Athena
- Azure: Blob Storage trigger on Azure Functions, Azure OpenAI in place of Bedrock, Synapse Analytics in place of Athena
- On-prem: A local object storage event (e.g. a filesystem watcher or a queue message) triggering a containerised function, a locally-hosted model via Ollama doing inference, Parquet written to local storage and queryable with DuckDB
Anyone who has written a C# background service — IHostedService, a BackgroundService loop, or a message consumer on a queue — will recognise this pattern. Something arrives, the service reacts, the result gets written somewhere. The event source changes (S3 vs. local queue), the inference step changes (Bedrock vs. Ollama), the output destination changes (Athena vs. DuckDB) — but the shape of the service doesn’t. That consistency is the point.
The Pydantic models and validators are entirely portable — they’re pure Python with no cloud SDK dependencies. BookMetadata would run identically in any of those environments. Parquet is a cloud-agnostic format. The S3 partitioning strategy (year=/month=/day=) is Hive-compatible and supported by Athena, BigQuery, Synapse, and DuckDB alike.
Where things genuinely differ is the model itself. Bedrock’s Claude 3 Haiku, Vertex AI’s Gemini, and Ollama’s LLaVA all have different capabilities, latencies, and costs. A prompt that produces clean BookMetadata from Haiku may need adjustment for a different model. The SYSTEM_PROMPT in constants.py and the output_type schema are the tuning surfaces — the rest of the code doesn’t change.
Conclusion
The line count drop from 508 to ~63 in lambda_function.py is a side effect of an architectural change.
The old extraction code was coupled to Bedrock’s API at every level: the anthropic_version payload key, invoke_model, response['body'].read(), the fallback JSON parsing chain. Every detail of how Bedrock works was embedded in the implementation. Changing the model provider means rewriting most of extract_metadata_with_bedrock.
The pydantic-ai Agent abstracts all of that. BinaryContent, run_sync, result.output — these don’t change when the underlying model does. Swapping from Bedrock to Vertex AI is a constructor change. The rest of the code is untouched because the rest of the code doesn’t know what model is running.
Beyond portability, the Agent is the right primitive for what comes next. A chain of function calls can be optimised; it can’t be extended without being rewritten. An agent can acquire new capabilities by registering tools. Future posts in the series will build on exactly that — adding tools that enrich extracted metadata, cross-reference ISBNs, and query external catalogues. None of that requires touching the extraction logic. It requires registering a tool.
The release is 1.1.0 in sudoblark.ai.bookshelf-demo. All posts are in the AI Vision Inference series.
Further Reading:
- Event-Driven Vision Inference with Bedrock, Pydantic, and Parquet — the previous post covering the overall architecture
- pydantic-ai documentation
- pydantic-ai-slim on PyPI
- AWS Lambda deployment package limits
Part 2 of 3 in AI Vision Inference