Refactoring monsternames-api to use modern Terraform

Part 3 of 3 in Infrastructure as Code (IaC)
Introduction
By late 2024 I’d been giving the Terraform with data structures and algorithms talk at a few events. The modularised-demo I used as a reference worked, but it’s an ETL pipeline — not the most accessible demo for a room that includes sysadmins and infrastructure engineers who’ve never touched a data pipeline. I wanted something everyone would immediately understand: a REST API you can call from a browser.
The monsternames-api was the obvious candidate. It had been running since 2020 as a Docker container on ECS with an RDS MySQL instance, managed through CircleCI and certbot. The original post covers the old architecture in detail — it ran, but it was the kind of architecture I’d actively avoid mentioning in interviews. Once I’d spent a few years provisioning Lambda and DynamoDB as standard, going back to look at that setup felt like finding old A-level coursework. Technically functional, obviously written before I knew better.
The refactor served two purposes. A concrete REST API demo for the talk, and finally putting the old infrastructure out of its misery.
The goal
By the end of this post, you’ll understand:
- How the data-structure-driven Terraform approach applies to a serverless REST API.
- How I replaced the Flask/PeeWee/MySQL application layer with a Lambda backed by DynamoDB.
- Why the config-file routing pattern mirrors the Terraform philosophy — and how the same idea scales beyond this use case.
- How I actually migrated the data from MySQL to DynamoDB without losing a single goblin name.
Prerequisites
- Familiarity with Terraform basics and the data structures and algorithms pattern.
- Basic Python and AWS Lambda knowledge.
- The original monsternames-api post gives useful context on the old architecture.
The old architecture, briefly
The original setup: a Flask app using PeeWee ORM against a MySQL RDS instance, running in a Docker container on an EC2 instance, with Nginx as a reverse proxy and certbot handling SSL. One t3.micro sitting idle for most of its life. I was paying for a persistent database that held a few hundred string values and barely changed.
Once I’d internalised serverless patterns — Lambda, DynamoDB, API Gateway — it was obvious that everything the old architecture was doing could be handled for a fraction of the cost and with no servers to maintain. The bill rounds to zero. The SSL certs are Amazon’s problem. There’s nothing to patch.
The replacement is API Gateway backed by a single Lambda function, DynamoDB as the data store, and an S3 bucket serving the Swagger UI — all provisioned in Terraform.
The Terraform
The Terraform side of this refactor was, by that point, straightforward. I’d been applying the data-structure pattern at clients for a couple of years — the monsternames-api was a chance to use it on something public-facing that I could reference in talks.
The structure follows the pattern directly. A modules/data/ directory holds the infrastructure definitions as plain data structures. An modules/infrastructure/ directory holds the modules that consume them. The environment layer wires them together.
Here’s the Lambda definition from modules/data/lambdas.tf:
/*
Data structure
---------------
A list of dictionaries, where each dictionary has the following attributes:
REQUIRED
---------
- name : Friendly name for the function.
- description : Human-readable purpose.
- handler : Python module path to the handler function.
- runtime : Lambda runtime identifier.
- role_name : Name of the IAM role to associate.
- zip_file_path : Path to the deployment package.
- timeout : Function timeout in seconds.
- memory : Memory allocation in MB.
OPTIONAL
---------
- lambda_layers : List of layer name aliases to attach.
- environment_variables : Map of environment variable key/value pairs.
*/
locals {
lambdas = [
{
name = "backend"
description = "Ingests and retrieves monsternames from DynamoDB"
handler = "backend_lambda.main.handler"
runtime = "python3.11"
role_name = "backend-lambda"
zip_file_path = "../../lambda-packages/backend.zip"
timeout = 900
memory = 256
lambda_layers = ["powertools-python"]
environment_variables = {
LOG_LEVEL = "DEBUG"
CONFIG_FILE = "config.ini"
}
},
]
}If you understand that block, you understand the Lambda infrastructure. The module underneath it creates the function, the IAM role, the CloudWatch log group, and the layer attachment — all from the data structure, with no configuration scattered across multiple files. Adding a second Lambda means adding another dictionary entry.
The IAM permissions follow the same principle: defined inline alongside the role that needs them, not in a separate file you have to cross-reference. The full infrastructure is in the repository if you want to read it end-to-end.
The initial refactor (v1.0.0) used versioned remote modules from Sudoblark’s module registry — the original DSA pattern. The repository has since been updated to use the three-tier approach in v2.0.0. The data layer shape described in this post is the same either way.
The Python
This is where the interesting decisions are.
The old Flask application had a class per monster endpoint, each wrapping the relevant PeeWee models. Adding a new monster type meant adding model classes, route handlers, and updating the test fixtures. The schema was MySQL — typed columns, explicit table definitions, a proper relational setup.
DynamoDB doesn’t need any of that for this use case. Every monster name table has the same schema: a single string attribute called value, used as the partition key. There are no joins, no foreign keys, no queries beyond “give me everything and I’ll pick one at random”. The simplicity of the data made the migration to a schema-light NoSQL store genuinely natural.
The service layer
The core logic lives in service.py. A GET request scans the relevant DynamoDB table and returns a randomly selected name:
def get_random_name(self) -> Tuple[int, Dict[str, Any]]:
response = {}
status_code = 200
for field, table_name in [
("firstName", self.first_name_table),
("lastName", self.last_name_table),
]:
if table_name == "none":
continue
table = self.dynamo_db_client.Table(table_name)
scan_result = table.scan()
items = scan_result.get("Items", [])
if not items:
return 500, {"error": f"No items found in {table_name}"}
response[field] = random.choice(items)["value"]
if "firstName" in response and "lastName" in response:
response["fullName"] = f"{response['firstName']} {response['lastName']}"
elif "firstName" in response:
response["fullName"] = response["firstName"]
return status_code, responseA POST request inserts a new name into the appropriate table, creating the table if it doesn’t already exist:
def create_name(self, payload: Dict[str, Any]) -> Tuple[int, Dict[str, Any]]:
for field, table_name in [
("first_name", self.first_name_table),
("last_name", self.last_name_table),
]:
value = payload.get(field)
if not value or table_name == "none":
continue
table = self._get_or_create_table(table_name)
table.put_item(Item={"value": value})
return 200, {"message": "Name(s) created successfully"}No ORM. No model classes. The entire data access layer is about thirty lines of Python, and it handles all six monster types identically.
The routing pattern
The Lambda handles every endpoint — all six monster types, GET and POST. Rather than hardcoding endpoint-to-table mappings in the handler, I put them in a configuration file:
[/goatmen]
first_name_table = monsternames.goatmen.first_name
[/goblin]
first_name_table = monsternames.goblin.first_name
last_name_table = monsternames.goblin.last_name
[/skeleton]
first_name_table = monsternames.skeleton.first_name
last_name_table = monsternames.skeleton.last_nameThe handler reads the request path, looks up the section in the config, retrieves the table names, and instantiates the service. Adding a new monster type is a new section in config.ini and a new DynamoDB table — no changes to the Lambda handler or the service layer.
This mirrors the Terraform philosophy: the code is generic, the data drives the behaviour. For six endpoints it’s overkill, but the same separation scales further than this. I’ve applied the same idea where configuration stored in DynamoDB drives the instantiation of separate infrastructure per tenant at runtime — the Terraform defines what a single instance looks like, and the data determines how many of them exist and with what configuration. The shape is the same at any scale.
Local testing and the migration
Before switching over, I needed confidence that the new Lambda worked correctly against a real DynamoDB instance, not mocked calls. I ran a local DynamoDB container and wrote integration tests against it — the DYNAMODB_ENDPOINT environment variable in the service layer exists specifically to support this. Once the tests were green locally, I was reasonably confident the service layer was correct.
The data migration was a two-step process. A script extracted every record from the old MySQL instance and wrote it to JSON. A second script read that output and submitted each record through the new API’s POST endpoints, letting the Lambda handle the DynamoDB writes through the same code path it would use in production. The deliberate choice not to write to DynamoDB directly meant the migration doubled as a live test of the write path — if something was wrong with create_name, I’d know before switching over.
No records were lost. Fat Jonny Punching survived the migration intact.
The result
The deployment went cleanly: GitHub Actions run. The API is live at monsternames.sudoblark.com.
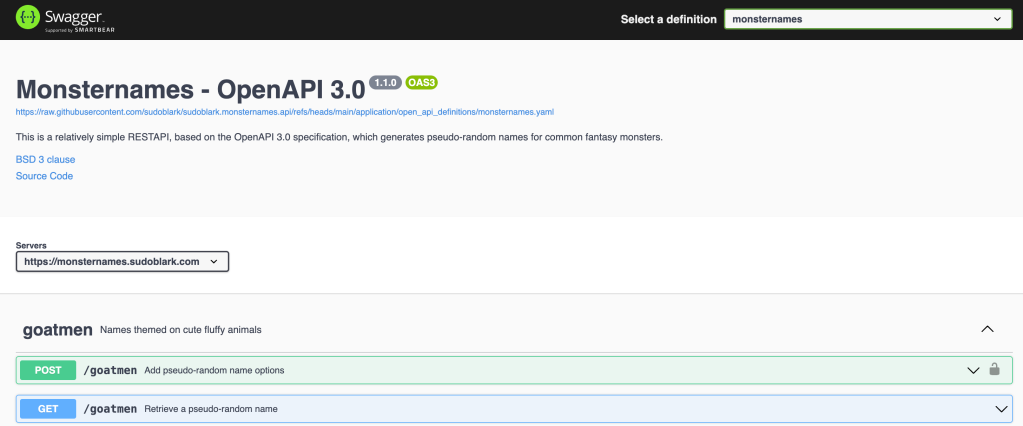
The infrastructure cost rounds to zero. There are no servers to patch, no certificates to renew, no RDS instance sitting idle between the rare occasions someone calls the API. The old setup was costing roughly twenty times what this one does.
It also works as a talk demo in a way the ETL pipeline didn’t. Calling a REST API in front of an audience and getting a goblin name back is immediately legible to anyone who’s ever used an API. The Terraform behind it — a directory of data structures and a handful of module instantiations — is equally legible. That combination is what I wanted.
Conclusion
The Terraform refactor was mechanical by this point — applying a pattern I’d developed and refined over a couple of years. The Python refactor was more interesting. Replacing a Flask/PeeWee/MySQL stack with a single Lambda backed by DynamoDB removed a lot of complexity, and the config-file routing pattern made the Python as data-driven as the infrastructure around it.
The migration process — local integration tests, export to JSON, re-ingest via the new POST API — is one I’d use again. Using the new service layer to perform the migration gave me an end-to-end test of the write path at the same time as moving the data. Doing it in two stages meant I could verify each half independently before flipping over.
The source code is at sudoblark.monsternames.api.
Further Reading:
- The dungeon crawler I never shipped, and the API I did — the original monsternames-api post; context on what was replaced and why
- Terraform with Data Structures and Algorithms — the pattern used for the infrastructure
- The Three-Tier Terraform Data Pattern — the evolution of the above, used on newer projects
- Talk: Terraform with Data Structures and Algorithms (November 2024) — the recorded talk that prompted this refactor
Part 3 of 3 in Infrastructure as Code (IaC)